
História do Machine Learning
O interesse por Machine Learning cresceu exponencialmente na última década, impulsionando uma transformação significativa na interação entre aplicações computacionais e seres humanos. Atualmente, utilizamos softwares de detecção de spam, sistemas de recomendação, marcação automática de fotos em redes sociais, assistentes pessoais ativados por voz, carros autônomos e smartphones com reconhecimento facial.
Esse crescente interesse é evidenciado pelo aumento no número de conferências, meetups, artigos, livros, cursos e buscas no Google relacionados ao tema. Profissionais e empresas buscam compreender e aplicar a aprendizagem de máquina, embora, por vezes, confundam o que é possível fazer com o que desejam alcançar. De acordo com o Gartner, até 2020, todos os softwares corporativos incorporariam alguma funcionalidade de Machine Learning.
Machine Learning envolve o uso de algoritmos para extrair informações de dados brutos, representando-os por meio de modelos matemáticos que permitem inferências sobre novos conjuntos de dados. Dentre os diversos algoritmos disponíveis, as redes neurais artificiais têm se destacado.
Embora as redes neurais artificiais existam desde a década de 1950, foi apenas recentemente que encontraram os ingredientes necessários para seu pleno funcionamento. Um desses ingredientes é o Big Data: o vasto volume de dados gerados com crescente variedade e velocidade possibilita a criação de modelos altamente precisos. Outro fator crucial foi o desenvolvimento da Programação Paralela em GPUs. As unidades de processamento gráfico permitem a realização de operações matemáticas em paralelo, especialmente com matrizes e vetores, elementos fundamentais em modelos de redes neurais artificiais. A combinação desses fatores — Big Data, processamento paralelo e modelos de aprendizagem de máquina — criou a “tempestade perfeita” que impulsionou a evolução atual da Inteligência Artificial.
A unidade básica de uma rede neural artificial é o nó (ou neurônio matemático), inspirado no neurônio biológico. As conexões entre esses neurônios matemáticos também se baseiam no funcionamento dos cérebros biológicos, especialmente na forma como se desenvolvem com o “treinamento”. Nos anos 1980 e início dos anos 1990, ocorreram avanços significativos na arquitetura das redes neurais artificiais. No entanto, a quantidade de tempo e dados necessários para obter bons resultados retardou sua adoção, levando ao chamado “Inverno da IA”.
No início dos anos 2000, com a expansão exponencial do poder computacional, surgiram técnicas computacionais antes inviáveis. O Deep Learning emergiu desse crescimento como o principal mecanismo para construir sistemas de Inteligência Artificial, vencendo diversas competições importantes de aprendizagem de máquina. O interesse por Deep Learning continua crescendo, com menções cada vez mais frequentes e soluções comerciais surgindo constantemente.
Nós, da 4tify, buscamos oferecer conhecimento avançado e de qualidade em nosso idioma, com materiais publicados no formato de posts em nosso blog e lançados semanalmente, visando contribuir para o crescimento do Deep Learning e da Inteligência Artificial no Brasil.
Acreditamos que com o compartilhamento do conhecimento, conseguimos criar uma grande rede colaborativa para evolução dos sistemas tecnológicos visando auxiliar empresas e governo na luta contra fakes e fraudes virtuais, aprimorando a segurança digital (cibersegurança ou segurança cibernética).
Redes neurais artificiais e o surgimento da IA (Inteligência Artificial)
As redes neurais artificiais têm uma história rica e evolutiva, marcada por avanços significativos desde meados do século XX.
Em 1943, o neurofisiologista Warren McCulloch e o matemático Walter Pitts propuseram um modelo computacional que simulava o funcionamento dos neurônios biológicos por meio de circuitos elétricos. Esse modelo, baseado na lógica de limiar, foi pioneiro na tentativa de replicar processos cerebrais em sistemas artificiais.
Posteriormente, em 1949, Donald Hebb introduziu a teoria de que as conexões neurais se fortalecem com o uso frequente, um conceito fundamental para a compreensão de como os seres humanos aprendem. Sua obra “The Organization of Behavior” destacou que, quando dois neurônios são ativados simultaneamente, a conexão entre eles se intensifica, formando a base do que hoje conhecemos como aprendizado hebbiano.
Com o avanço da computação na década de 1950, tornou-se possível simular redes neurais hipotéticas. Nathanial Rochester, dos laboratórios da IBM, foi um dos pioneiros nessa tentativa, embora suas primeiras experiências não tenham obtido sucesso. Em 1956, o Projeto de Pesquisa de Verão de Dartmouth sobre Inteligência Artificial impulsionou tanto a IA quanto as redes neurais, estimulando pesquisas focadas no processamento neural.
Nos anos subsequentes, John von Neumann sugeriu a imitação de funções neurais simples utilizando relés telegráficos ou tubos de vácuo. Paralelamente, o neurobiólogo Frank Rosenblatt desenvolveu o Perceptron, inspirado no olho da mosca, que realizava grande parte do processamento visual. O Perceptron, construído em hardware, é uma das redes neurais mais antigas ainda em uso, capaz de classificar entradas contínuas em duas classes distintas. Contudo, suas limitações foram evidenciadas por Marvin Minsky e Seymour Papert no livro “Perceptrons”, publicado em 1969.
Em 1959, Bernard Widrow e Marcian Hoff, de Stanford, desenvolveram os modelos “ADALINE” e “MADALINE”, destinados ao reconhecimento de padrões binários. Esses modelos foram aplicados para prever bits em transmissões telefônicas, representando um avanço significativo na aplicação prática de redes neurais.
A década de 1980 testemunhou um ressurgimento do interesse por redes neurais, especialmente com a introdução de redes de múltiplas camadas e o desenvolvimento do algoritmo de retropropagação (backpropagation), que permitiu o treinamento eficaz de redes mais complexas. Conferências internacionais, como a primeira Conferência Internacional sobre Redes Neurais do IEEE em 1987, atraíram milhares de participantes, refletindo o crescente entusiasmo na área.
Nos anos 2000, com o aumento exponencial do poder computacional e a disponibilidade de grandes volumes de dados, as redes neurais profundas (deep learning) emergiram como a principal abordagem para a construção de sistemas de inteligência artificial. A capacidade de treinar redes com múltiplas camadas revolucionou áreas como reconhecimento de voz, processamento de imagens e tradução automática.
Atualmente, as redes neurais artificiais são fundamentais em diversas aplicações tecnológicas, desde assistentes virtuais até veículos autônomos, demonstrando a importância contínua dessa área de pesquisa no avanço da inteligência artificial.
Observe, no exemplo abaixo, a complexa estrutura de alguns modelos de redes neurais e suas interconexões.
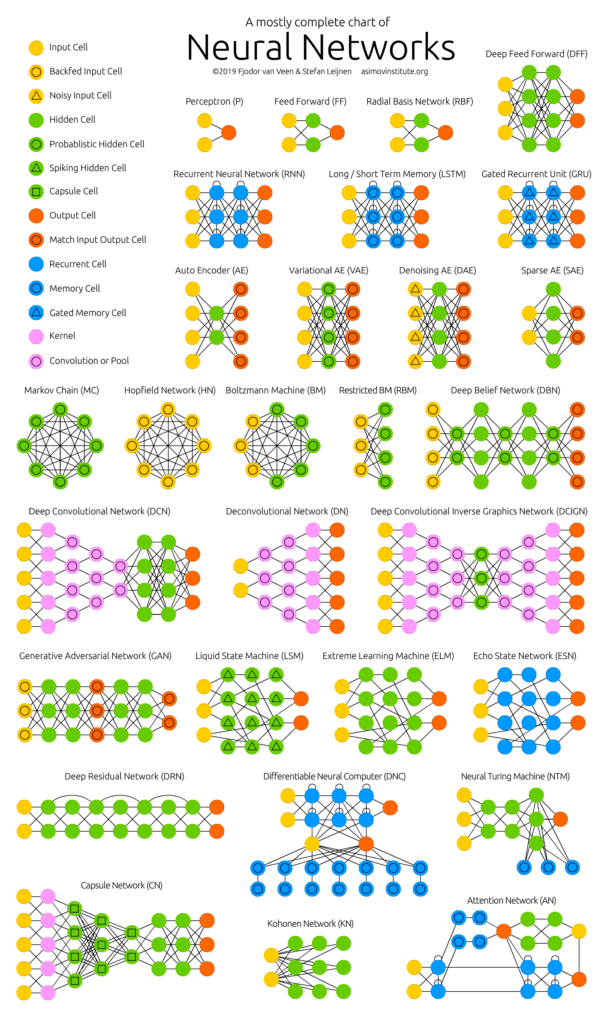
Exemplo de Redes Neurais. Fonte: Deep Learning Zoo
Aprendizado profundo e a evolução das clássicas redes neurais
As redes neurais artificiais profundas, ou deep learning, representam uma subárea da aprendizagem de máquina que utiliza algoritmos para processar dados de maneira semelhante ao cérebro humano. Essas redes são compostas por múltiplas camadas de neurônios matemáticos que permitem a compreensão de fala, reconhecimento de objetos e processamento de linguagem natural.

Comparativo entre rede neural simples e profunda. Fonte: Deep Learning Zoo
Em uma rede neural profunda, a informação é transmitida através de diversas camadas: a camada de entrada recebe os dados iniciais, as camadas ocultas processam essas informações e a camada de saída fornece o resultado final. Cada camada aplica funções de ativação específicas para transformar os dados e extrair características relevantes de forma automática, sem a necessidade de intervenção humana.
O deep learning tem sido fundamental para avanços em áreas como visão computacional, reconhecimento de fala e processamento de linguagem natural. Sua capacidade de superar métodos tradicionais de aprendizagem de máquina em diversas tarefas é notável, embora, por vezes, difícil de explicar. As redes neurais profundas evoluíram a partir das redes neurais artificiais, cuja história remonta à década de 1940, marcada por desafios e progressos significativos.
O interesse por deep learning tem crescido exponencialmente, com pesquisas sendo publicadas em revistas renomadas e ampla cobertura na mídia. Aplicações notáveis incluem a vitória no jogo Go, desenvolvimento de veículos autônomos, diagnósticos médicos e até a criação de obras de arte.
Os primeiros algoritmos de deep learning com múltiplas camadas de características não lineares foram desenvolvidos por Alexey Grigoryevich Ivakhnenko e Valentin Grigor’evich Lapa em 1965. Eles utilizaram modelos profundos com funções de ativação polinomial, analisados por métodos estatísticos, selecionando os melhores recursos em cada camada para serem encaminhados à próxima. Embora não utilizassem backpropagation, aplicavam mínimos quadrados camada por camada, ajustando as camadas anteriores independentemente das posteriores.
No final da década de 1970, a pesquisa em inteligência artificial enfrentou desafios devido a promessas não cumpridas, resultando em redução de financiamento. Apesar disso, alguns pesquisadores continuaram seus trabalhos de forma independente. Em 1979, Kunihiko Fukushima desenvolveu o Neocognitron, uma rede neural artificial com múltiplas camadas de convolução e agrupamento, capaz de aprender a reconhecer padrões visuais. Embora semelhante às redes modernas, o Neocognitron era treinado com estratégias de reforço de ativação recorrente e permitia ajustes manuais nos pesos das conexões para aprimorar o reconhecimento de características importantes.
Muitos conceitos do Neocognitron permanecem relevantes até hoje. O uso de conexões de cima para baixo e avanços nos métodos de aprendizagem possibilitaram o desenvolvimento de diferentes tipos de redes neurais. Quando mais de um padrão é apresentado simultaneamente, o Modelo de Atenção Seletiva permite reconhecer cada padrão individualmente, alternando a atenção entre eles – semelhante ao processo humano de multitarefa. Um Neocognitron moderno é capaz de identificar padrões incompletos, como um número “5” parcialmente desenhado, e até mesmo completar a imagem, preenchendo as lacunas. Esse processo é conhecido como “inferência”.
O Backpropagation, técnica que utiliza erros para ajustar modelos de Deep Learning, deu um grande salto em 1970, quando Seppo Linnainmaa apresentou sua tese com um código FORTRAN para implementar a ideia. Contudo, somente em 1985 o conceito foi aplicado a redes neurais, quando Rumelhart, Williams e Hinton demonstraram sua eficácia ao gerar representações distribuídas inovadoras. Essa descoberta trouxe debates na psicologia cognitiva sobre se o pensamento humano depende da lógica simbólica ou de representações distribuídas. Em 1989, Yann LeCun demonstrou o uso prático do Backpropagation no Bell Labs, combinando-o com redes convolutivas para interpretar dígitos manuscritos – tecnologia empregada na leitura de cheques.
Entre 1985 e 1990, a área enfrentou o chamado “inverno da IA”, marcado por expectativas inflacionadas que geraram desilusão entre investidores. Mesmo assim, avanços notáveis ocorreram. Em 1995, Dana Cortes e Vladimir Vapnik criaram as Support Vector Machines (SVMs) para mapear dados similares, enquanto Sepp Hochreiter e Juergen Schmidhuber introduziram as redes de Long Short-Term Memory (LSTM) em 1997, fundamentais para modelos recorrentes.
O próximo marco evolutivo foi em 1999, quando o uso de GPUs acelerou o processamento de dados, tornando as redes neurais mais competitivas em relação às SVMs. Embora inicialmente mais lentas, as redes neurais se destacaram por melhorar continuamente com o aumento de dados de treinamento. No início dos anos 2000, surgiu o problema do Vanishing Gradient, que impedia camadas superiores de aprenderem com eficácia. Esse obstáculo foi mitigado com técnicas como pré-treino camada a camada e o uso de funções de ativação otimizadas.
Em 2001, o relatório do Grupo META (hoje Gartner) destacou o impacto crescente do Big Data, enfatizando a necessidade de preparar-se para a explosão de dados. Em 2009, Fei-Fei Li, professora de IA em Stanford, lançou o ImageNet, uma base de dados com mais de 14 milhões de imagens rotuladas, essencial para treinar redes neurais. Li destacou que “os dados impulsionam o aprendizado”, antecipando a revolução que o Big Data traria.
Por volta de 2011, melhorias nas GPUs eliminaram a necessidade de pré-treino, permitindo que arquiteturas como a AlexNet vencessem competições internacionais em 2011 e 2012, graças ao uso de unidades lineares retificadas (ReLUs) para otimizar a velocidade. Em 2012, o Google Brain apresentou o “Experimento do Gato”, utilizando aprendizado não supervisionado para treinar redes com 10 milhões de imagens do YouTube. O sistema reconheceu padrões complexos, como rostos humanos e imagens de gatos, mostrando o potencial dessa abordagem.
Hoje, o Deep Learning é central para o avanço da inteligência artificial e o processamento de Big Data, transformando setores inteiros. Aqueles que dominarem essa tecnologia estarão na vanguarda da nova era digital, moldando o futuro de maneira decisiva.
Em nossos sistemas, utilizamos o algoritmo próprio da 4tify com inteligência artificial e aprendizado neural profundo para monitoramento e identificação automática de sites fakes. Quanto mais o sistema é alimentado com dados, maior o aprendizado automático e maior a precisão e agilidade para executar essa tarefa.
Seguimos, ainda, ajustando a todo instante nosso código, bem como verificando e direcionando o aprendizado neural artificial para que siga o caminho correto através da visão atenta de nossa equipe de especialistas em segurança digital e feedback de nossos clientes, intensificando aceleradamente nossa eficiência.

